Picture yourself in this all too common scenario. You've been developing a glorious application for weeks or months, and you're near the end. It's your masterpiece, a real showstopper, your veritable magnum opus of creativity and cleverness. You've gotten to the detailed testing stage, and you're confident that everything will come together smoothly. The application will run flawlessly and you'll be a hero in the eyes of your colleagues and customers. Under budget, ahead of schedule, with a sexy GUI and clean block diagram. Thanks to LabVIEW, you've been able to test each and every one of your functional modules as you've developed them, and stand-alone, each one is bug free. The sun is shining, the flowers are blooming, and life is great.
Then you start running the integrated application. Suddenly, things don't work so well. Routines that you thought were completely debugged are throwing errors you've never seen before. Or worse... nothing is causing an error, but your test inputs are not producing the correct results. Things are behaving in a weird and unpredictable manner. Testing is going poorly and taking far more time than you had budgeted. Your customer is demanding to know when you'll be finished and your answers are growing vague. You can see your schedule leeway rapidly evaporating and you're losing confidence in your ability to deliver. You haven't seen your wife and kids in days, the dark clouds are closing in around you, and life sucks.
How many of us have faced this looming disaster with fear and trepidation? What could you have done to reduce the anxiety and make testing at least a little bit more predictable? I won't suggest that there is one single, silver-bullet solution that will magically convert your software dung beetles into amethyst scarabs. However, there is one really simple discipline that will make your job of isolating bugs far simpler: put error handling into every single subVI that you write.
Sounds too simple? Not too simple; just simple enough to be easy and very useful. Let's review first the easiest way to approach this.
The most basic subVI error handling consists of a case statement enclosing all of your functional code in each module, with the input error cluster wired to the selector terminal. The error case will execute nothing, and merely pass through the error cluster to the output. In the non-error case, where your actual code resides, you wire the error cluster through your code as possible, picking up all elements that handle errors (familiar examples include file I/O and synchronization functions). In this manner, if the VI kicks an error, it passes it out to the next VI in line. For any VI, input errors inhibit any further processing.
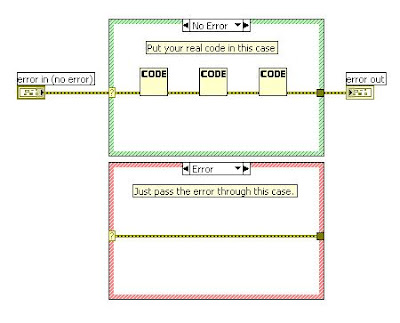
The most obvious result is that the source of any error produced will be clear in any chain of subVI's. Put a probe on the output error clusters in a successive chain, run your code, and magically, the source of the error becomes painfully apparent. Errors can be isolated easily and unambiguously. For no other reason, this simple approach is worth its weight in gold.
With error clusters in and out of every subVI, you can enforce data flow dependency that might otherwise be difficult or impossible. With this, you can ensure the steps through which your program flows. Results? You know exactly what executes when. You dramatically reduce the possibilities of timing ambiguity or race conditions. You eliminate the need for artificial ways to guarantee program execution order, such as sequence structures. And you can probe or breakpoint all intermediate values, step-by-step, from one VI to the next.
As a useful side-effect, putting error in and out clusters on all of your subVI's also helps to standardize the icon/connector panes of your work. Many authors have advocated picking a single pattern and using it on all of your work; popular ones include the 4-2-2-4 and 5-3-3-5 terminal layouts.
There are certainly more sophisticated approaches to error handling than what I've presented here. Peter Blume devotes an entire chapter to the subject in his book, for example. The point of this article is this:
just start doing it. You'll see the benefits immediately. First, get into the habit of including at least the most basic error handling in your subVI's. Then you can start to get fancy.
The scenario described in my opening paragraphs is one that I've either witnessed or lived through too many times. This approach is so easy to do, and such a powerful tool to help make your code more robust and easier to debug, that there's no excuse not to do it.









